CS: Data Structures
학습 목표
- 배열의 크기 조정하기
- 연결 리스트: 도입
- 연결 리스트: 코딩
- 연결 리스트: 시연
- 연결 리스트: 트리
- 해시 테이블
- 트라이
- 스택, 큐, 딕셔너리
배열의 크기 조정하기
만약 배열의 크기를 키우고 싶다면 어떻게 해야 할까?
먼저 새로운 메모리를 할당하고 기존의 값을 전부 옮겨주는 방식이 있을 것이다. 이 작업은 O(n) 시간이 소요될 것이다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *list = malloc(3 * sizeof(int));
// 포인터 잘 선언됐는지 확인
if (list == NULL)
{
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
// 새로운 메모리 할당
int *tmp = malloc(4 * sizeof(int));
if(tmp == NULL)
{
return 1;
}
for (int i = 0; i < 3; i++)
{
tmp[i] = list[i];
}
tmp[3] = 4;
free(list);
list = tmp; // list가 tmp와 같은 곳을 가리키도록
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i])
}
free(list);
}
위 과정을 쉽게 해주는 함수가 있다. 바로 realloc를 이용하면된다.
int main(void)
{
int *list = malloc(3 * sizeof(int));
if (list == NULL)
{
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
// tmp 포인터에 메모리를 할당하고 list의 값 복사
int *tmp = realloc(list, 4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
list = tmp;
list[3] = 4;
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
free(list);
}
연결 리스트: 도입
배열은 랜덤 접근이므로 인덱싱하기 쉽지만 새로운 값을 추가하기엔 O(n)의 시간이 걸린다는 단점이 있다. 이를 위해서 연결리스트 개념을 사용해볼 수 있는데 이는 메모리의 여러 군데에 값을 저장을 하고 그 메모리 주소만 기억하고 있다면 순차적 접근으로 인덱싱할 수 있다. 이는 새로운 값을 추가하기 쉽다는 장점을 가지고 있다.
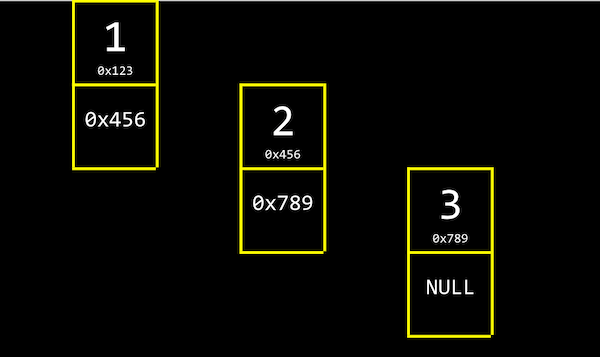
// 구조체 안에서 node를 쓰기 위해 node를 함께 명시해준다.
typedef struct node
{
int number;
struct node *next;
}
node;
연결 리스트: 코딩
처음에 비어있는 연결 리스트를 구현하는 법은 첫 노드를 NULL로 초기화하면 된다.
맨 뒤에 node를 추가하고 싶다면 반복문으로 일단 next가 NULL인 노드를 찾는다. 그 next의 주소를 임시 변수에 넣어서 업데이트 한 다음 NULL이 없을 때 임시 변수의 next에 추가할 노드를 넣는다.
만약 맨 앞에 추가하고 싶다면 먼저 리스트를 새로운 노드에 연결하고 싶다고 생각하겠지만 이것은 문제가 생긴다. 왜냐하면 다음 연결리스트가 연결이 사라져서 잃어버리게 되어 접근할 수 없다. 이를 메모리 누수라고 한다. 그렇기 때문에 먼저 새로운 노드의 next를 처음 node와 연결하고 난 뒤 리스트를 새로운 노드와 연결하면 된다.
만약 중간에 추가하고 싶다면 반복문으로 넣고 싶은 부분에 새로운 노드 next와 그 이후 노드와 연결하고 이전 노드의 next에 새로운 노드를 연결하면 된다.
이러한 방법으로 진행되기 때문에 맨 앞과 뒤에 노드를 추가하는 것은 중간에 추가하는 것보다 쉽다.
연결리스트를 초기화하고 첫 번째 노드에 값을 넣는 코드이다.
typedef struct node
{
int number;
struct node *next;
}
node;
int main(void)
{
node *list = NULL; // 초기화
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킵니다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 1; // (*n).number와 동일한 의미이다.
n->next = NULL;
list = n;
}
연결 리스트: 시연
연결리스트는 임의 접근이 불가능하기 때문에 이진 탐색을 할 수 없다. 대신 새로운 값을 몇 개이든 추가할 수 있다는 아주 좋은 장점이 있다. 그래서 탐색은 O(N)이 걸린다. 삽입의 경우 최악의 경우 O(N)이 된다.
#include <stdio.h>
#include <stdlib.h>
// Represents a node
typedef struct node
{
int number;
struct node *next;
}
node;
int main(void)
{
// list of size 0
node *list = NULL;
// Add number to list
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 1;
n->next = NULL;
list = n;
// Add number to list
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 2;
n->next = NULL;
list->next = n;
// Add number to list
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
list->next->next = n;
// Print list
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// Free list
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}
연결 리스트: 트리
연결 리스트의 단점과 배열의 단점을 보완한 자료구조가 있다. 바로 트리이다. 연결리스트에서 1차원적이라면 트리에서는 2차원으로 구성되어 있다고 할 수 있다. 왼쪽이 항상 작고 오른쪽이 항상 크다면 이진 탐색 트리라고 한다. 이로써 연결리스트에서 할 수 없었던 이진 탐색이 가능해졌다!
그렇지만 트리에 막 넣다보면 균형이 맞지 않는 문제가 생긴다. 이를 알고리즘으로 해결할 수 있다.
typedef struct node
{
int number;
struct node *left;
struct node *right;
} node;
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
else {
return true;
}
}
탐색과 삽입 시간은 모두 O(log n)이 된다.
해시 테이블
더 작은 시간 복잡도를 갖고 싶은 경우 해시 테이블을 사용할 수 있다. 이도 마찬가지로 배열과 연결리스트를 합친 것이다. 세로로 배열을 만들고 가로로 연결 리스트를 만들면 된다. 만약 연결 리스트를 만들어야 하는 상황이면 기준을 변경해 배열을 더 늘리면 실행 시간은 줄어들 것이다.
그렇지만 이론적으로 한 칸에 많은 아이템이 들어오면 최악의 경우 O(n)이 걸린다. 그러나 알고리즘이 이보다 빠르게 작동하게 만들긴 한다. 그래서 보통 일반적으로 최대한 많은 바구니를 만드는 해시 함수를 사용하기에 실행 시간은 O(1)에 가깝다.
트라이
이번에 소개할 트라이 자료 구조는 트리 형태이지만 노드가 배열로 이루어져 있다. 이는 문자열의 길이에 한정되므로 대부분 크지 않은 상수값을 가져 탐색과 삽입이 O(1)이 걸려 좋지만 대신 아주 많은 양의 메모리를 소비하게 된다는 단점이 있다.
스택, 큐, 딕셔너리
큐는 FIFO 방식으로 가장 먼저 들어온 값이 가장 먼저 나가는 자료 구조이다. 스택은 LIFO 방식으로 가장 나중에 들어온 값이 가장 나중에 나가는 자료 구조이다. 딕셔너리는 키와 값 요소로 이루어져 있어 해시 테이블과 동일한 개념이라고 볼 수 있는 자료 구조이다.
수강 완료!

강의명
- 부스트코스 : 모두를 위한 컴퓨터 과학 (CS50 2019)
댓글남기기